
Using GPT to Accelerate "Matching/Co-Creation" Among 1,105 Teams in the "Expo" Project with a LINE Bot

This article was written on May 30, 2023, at 8:52 PM on note, a content platform for Japanese creators.
Have you ever heard of "TEAM EXPO 2025"?

Some of you might recognize it from the distinctive character in the top left corner of the image—yes, it’s part of the Osaka Expo project.
"TEAM EXPO 2025" is a participatory program where diverse teams take on various initiatives to shape the future beyond the Osaka-Kansai Expo.
https://team.expo2025.or.jp/
As described above, it is essentially a platform where projects are proposed and carried out collaboratively.

Currently, there are approximately 1,105 co-creation challenges within this initiative. Each challenge has its own dedicated webpage showcasing its activities, as seen in the screenshot below.

The Expo is still two years away, yet over 1,000 teams have already gathered, demonstrating incredible enthusiasm! However, this leads to a major challenge:
Despite being a "Co-Creation Challenge," the sheer number of teams makes it difficult for them to recognize one another, potentially hindering collaboration.
To address this issue, we leveraged the generative model team from Japan’s largest AI community, "CDLE (Cedle)," alongside Kaname Project, where I serve as CEO, and Crystal Inc., where I am an AI technical advisor. Together, we developed a GPT-powered application to solve this matching problem, which we showcased at "TEAM EXPO 2025 Meeting #2."

Breaking Down the Problem:
We want to facilitate meaningful matches among 1,105 teams.
However, team information consists of roughly 2,000-character text descriptions.
To tackle this, we proceeded as follows:
1. Summarizing Team Information into 300 Characters Using GPT
Data Acquisition: The Expo’s administrative office kindly provided CSV-format data containing text information for each co-creation challenge. Thank you again!
Summarization Approach: Rather than using the raw text directly, we optimized it for better matching by summarizing it along three key perspectives:
Goals (What they aim to achieve)
Offerings (What they can provide)
Needs (What support they are looking for)
The final summary was condensed to approximately 300 characters.
Example Prompt:
Summarize the content below according to the specified "perspectives," and output in the "output format." Each summary should be around 100 characters.
### Perspectives
- Goals:
- Offerings:
- Needs:
### Text
<Original team description>
### Output Format
# Type: Co-Creation Challenge
# Team Name:
# Goals:
# Offerings:
# Needs:Since manually running this for each team in ChatGPT would be tedious, we automated the process using LangChain.
2. Converting Summarized Text into Vectors for Matching (Using GPT’s Embedding Function)
Embedding & Matching: One of GPT’s API features allows converting text into embedding vectors. These vectors represent text in a way where similar content is mapped closer together in a high-dimensional space.
Various matching methods can be considered:
Comparing the overall distance of the summarized text (matching teams with similar descriptions).
Matching "Offerings" with "Needs" (creating support-based connections).
Combining "Offerings" and "Needs" while filtering based on "Goals" (ensuring aligned direction in support connections).
For this experiment, we used the simplest approach—measuring the overall text similarity.
Distance Calculation: Matching 1,105 teams using full-distance calculations results in over 1.2 million comparisons (1,105 x 1,105). Instead of computing this on demand, we precomputed and stored the results.
We used cosine similarity to measure the vector distances:
Cosine similarity: A method to quantify the similarity between two vectors by calculating the cosine of the angle between them.
3. Listing the Closest Co-Creation Challenges and Final Matching by GPT
GPT-Based Matching: Finally, GPT performed the actual matching. While GPT can generate match suggestions, it has token limitations (a cap on the number of characters it can process at once).
Matching 10 teams is manageable, but handling all 1,105 teams in a single request exceeds GPT’s token limit. Therefore, we first narrowed down the candidates.
Using precomputed similarity scores, we filtered out the top 10 potential matches for each team before passing them to GPT.
Example Matching Prompt:
From the "Co-Creation Challenge List" below, select three that seem to be the best matches for "Me," and provide a reason (max 100 characters per reason). Follow the "Output Format."
### Me
<Summary of the team looking for matches>
### Output Format
Co-Creation Challenge 1:
Reason:
Co-Creation Challenge 2:
Reason:
Co-Creation Challenge 3:
Reason:
### Co-Creation Challenge List
<Summary of the most similar co-creation challenge>
︙
<Summary of the 10th most similar co-creation challenge>Generating the Co-Creation Challenge List: In this experiment, we simply selected the 10 most textually similar challenges based on cosine similarity. However, by tweaking this step, we could explore different matching approaches.
Application Implementation
With the overall design completed, we implemented the application with the following structure. The front-end development was handled by Yano.
For more details, please refer to the blog post below. Here, we will provide a brief excerpt and introduction.
https://cdle.jp/blogs/13efce60c656
Overall Architecture
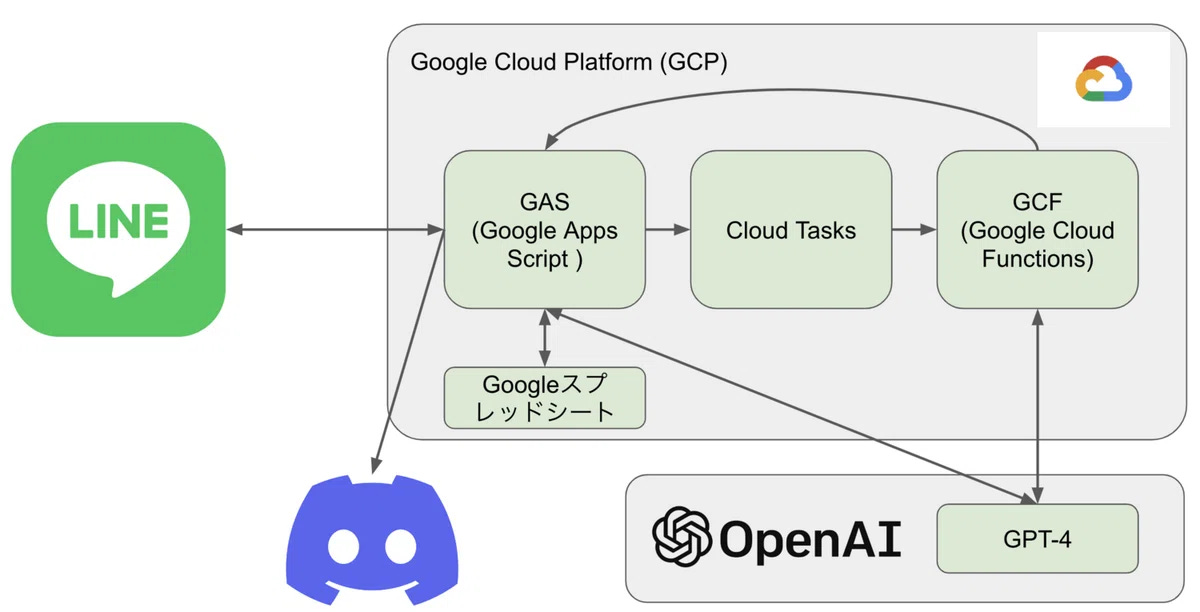
The system is implemented as a LINE bot. The overall process consists of three main steps: summarization, embedding vectorization, and matching, all powered by GPT. However, when a user makes an inquiry, only the final matching API is executed in real time.
Since the similarity between co-creation challenges is precomputed, the system simply retrieves the relevant data from the database and automatically generates the final matching prompt.
In terms of API usage:
Summarization: GPT-3.5
Embedding Vectorization: A dedicated model
Final Matching: GPT-4
Each model is used according to its specific purpose.
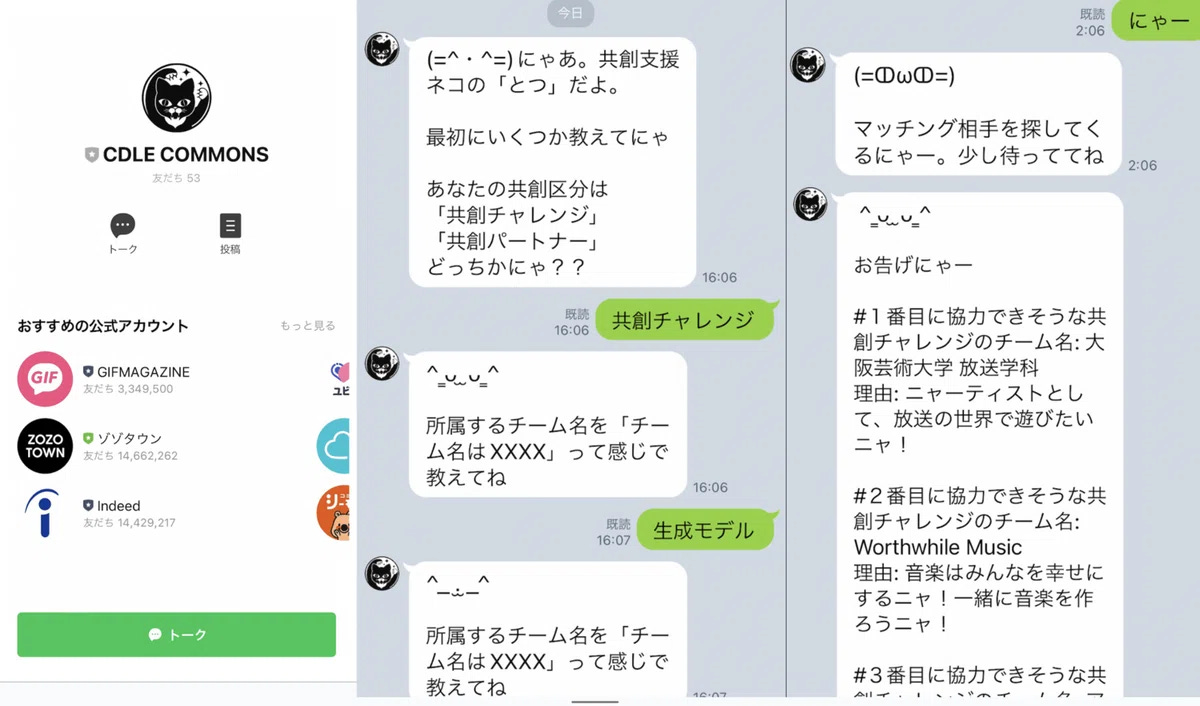
The chatbot features a cat-like character. When users type "Meow", the bot finds a matching partner for them.
Thanks to this system, we had a great turnout at TEAM EXPO 2025 Meeting #2, with many participants signing up. Thank you all for your support!
A Quick Announcement
At Kaname Project, we specialize in AI-driven development, proof-of-concept (PoC) experiments, and consulting services using GPT and other cutting-edge technologies.
If you’re interested in exploring such development opportunities, feel free to reach out! We look forward to collaborating with you.
https://prtimes.jp/main/html/rd/p/000000001.000112864.html
Introducing "OMOCha"—AI-Powered DX Consulting & PoC Services
Kaname Project has launched "OMOCha" (pronounced Omocha), a DX consulting and PoC service powered by a team with 25 years of AI expertise.